post titan typescript react react-native
First, a little context. I’d taken a long break from lifting weights and knew I had to get back to it. I thought what better way to motivate myself than to build some tech first 🙂. I also had the habit of starting many personal projects but usually abandoning them. This is where I thought it’d be fun to actually build a usable product from scratch. This would also give me an opportunity to spend some time in domains I don’t have a lot of direct experience with - things like marketing, design & customer support (You can read more about my motivations at introducing-titan-workout-tracker).
Picking the right tool for the job is absolutely crucial, especially when you have limited time to spend on it. I didn’t want to needlessly complicate things by picking the wrong set of technologies, especially on a one-person project like this.
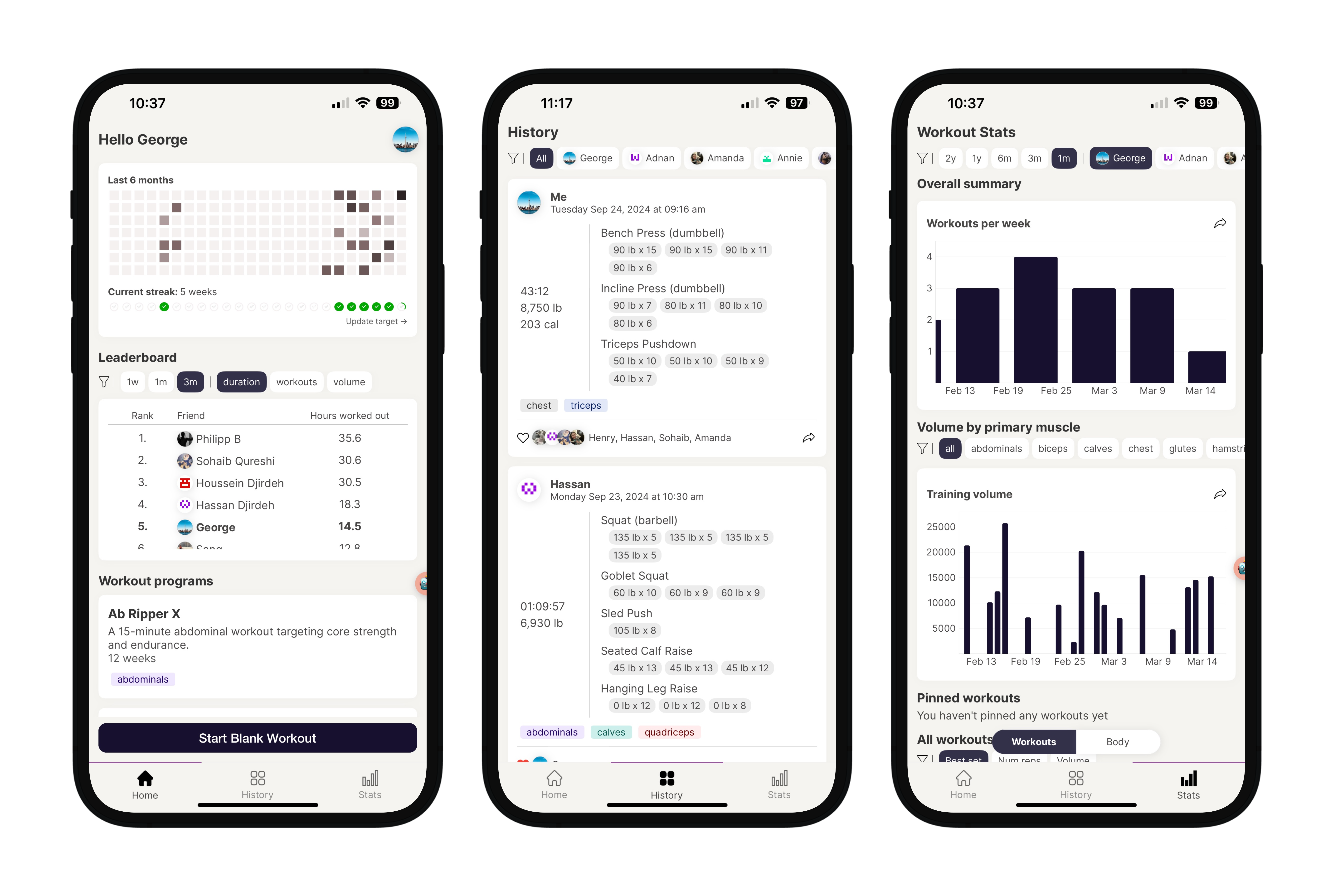
What I wanted to achieve here was a cleanly designed, intuitive and functional workout tracker that runs on any phone. Additionally I wanted it to have a social component as some of my friends are into lifting too, and I thought it’d be cool to be able to follow each other’s progress, and even work out together live.
There are a few main pieces to the stack behind something like this. Broadly speaking they are:
- Frontend tech
- Backend tech
- Database & ORM
- Infrastructure
- Monitoring
- Product analytics
Frontend
High level my options, to start, were:
- Native apps built in kotlin for Android + swift for iOS
- Frameworks that package up web apps to run on mobile (eg: Capacitor or Cordova)
- Progressive Web App (PWA)
- Flutter
- React native
The requirements I had for this part of the stack were:
- The end product should be an app that can run on Android and iPhone
- Pretty much any of the above tech should meet this requirement
- The app should look and feel native (i.e I didn’t want it to be a repackaged web app)
- This eliminated the PWA route, and frameworks like Capacitor. It’s hard to get web components to look truly native.
- I should be able to iterate quickly
- This eliminates building two separate apps in two different technologies (swift / kotlin)
- This also eliminated Flutter for me, as learning a new language (Dart) would take a little longer. Flutter also has a smaller community than react native, which also means there are fewer third party libraries for it.
- The App Store and Play Store both have a review process to get updates out. While this exists to ensure quality, it can slow things down quite a bit (particularly on the App Store). The React native ecosystem has tools like Expo Updates and CodePush that enable much quicker Over the Air updates especially for small changes.
- The codebase should be maintainable long term
- Maintaining 2 codebases with native code would be hard to do
- This is a personal opinion, but this requirement also eliminated Flutter for me because of its association with Google. I’m personally afraid of building on top of google tech because of their history with breaking changes (eg: angular), and with shutting down projects with little warning (too many examples to list). I wanted to build on a mature technology that had a rock solid community around it.
This led me to React Native with typescript for the main app product. I’ve got a decent bit of experience with this tech, know many of it’s pitfalls and how to avoid them, and it has a large community around it. I used the Expo framework as I didn’t want to reinvent the wheel to solve common problems.
I picked NextJS for the product’s (mostly) static site. The main thing I wanted to optimize for here was loading speed, something NextJS does quite well if you use Server Side Rendering (SSR) .
Backend
I had many requirements in common here with the frontend, and a few additional considerations. My requirements were:
-
Quick iteration speed & ease of maintenance
- I wanted something opinionated and ‘batteries included’, where I don’t have to string together my own framework. I have some experience with Rails, and love these attributes about it. While I appreciate how fast it is to start out with, the lack of static typing IMO makes it harder to maintain in the long term.
- To an extent I wanted to minimize technology sprawl. It would be a plus if the tech I picked here used the same language as the frontend (I could then use the same formatting, linting and other tooling setup in a monorepo).
-
Control & flexibility
- An option was to go serverless and build the app using something like Firebase + Cloud Functions or AWS Lambda, but I had concerns about them not being as flexible as I wanted it to be. I didn’t want my business logic to be limited by what the service supports.
- I also didn’t want my code to be vendor locked into a specific technology, one that it might outgrow someday.
- I figured I’d have the most control if I built my own backend with an open source community framework.
-
Cost
- Predictable and low cost was another attribute I was looking for, since I didn’t know whether this project would succeed and bring in enough revenue to cover costs.
- For me this meant avoiding certain services that are known to be really easy to start with but that aren’t as cost efficient - eg: Firebase, Supabase.
In the end I settled on NestJS. It provides a structured, scalable framework for building server-side applications with TypeScript. It naturally encourages a very modular architecture, supports dependency injection which makes testing easier, and incorporates sane design patterns. It also has a pretty rich ecosystem of libraries.
If I were to start the project today, I’d also consider AdonisJS for its ‘batteries-included’ nature similar to Rails.
Database and ORM
The requirements I had for my database were:
- Have a strict, consistent schema
- Support normalized data and efficient, complex queries with JOINs
- Support transactions (i.e if a part of an operation fails, the part that succeeded is rolled back) and other ACID guarantees
- Allow for the schema to evolve over time, without leading to inconsistent data
- Be scalable
All this, arguably except (5), meant I’d need a relational database. It would mean that scaling would have to be vertical instead of horizontal, but it would be a fair tradeoff given all the other benefits.
I started the project with sqlite. However, soon after getting a few real users I moved onto postgres because I was running into bottlenecks with concurrent writes on sqlite.
I wanted my backend application code that connects to the database to be maintainable (i.e I didn’t want to have raw sql queries). This meant I needed an ORM. Using an ORM gives me a higher level of abstraction to interact with data, and also makes it easier to switch out the underlying database without a lot of code changes.
The main contenders here were Sequelize, TypeORM, Prisma and Knex. I picked Prisma for a few reasons:
- Strong type safety with typescript
- Intuitive, GraphQL like query structure
- How your database schema can be defined (and later updated) through an intuitive schema.prisma file. It also has very good IDE support on VSCode.
I’m also a big fan of ActiveRecord on Rails, so I think TypeORM would’ve been nice to work with too.
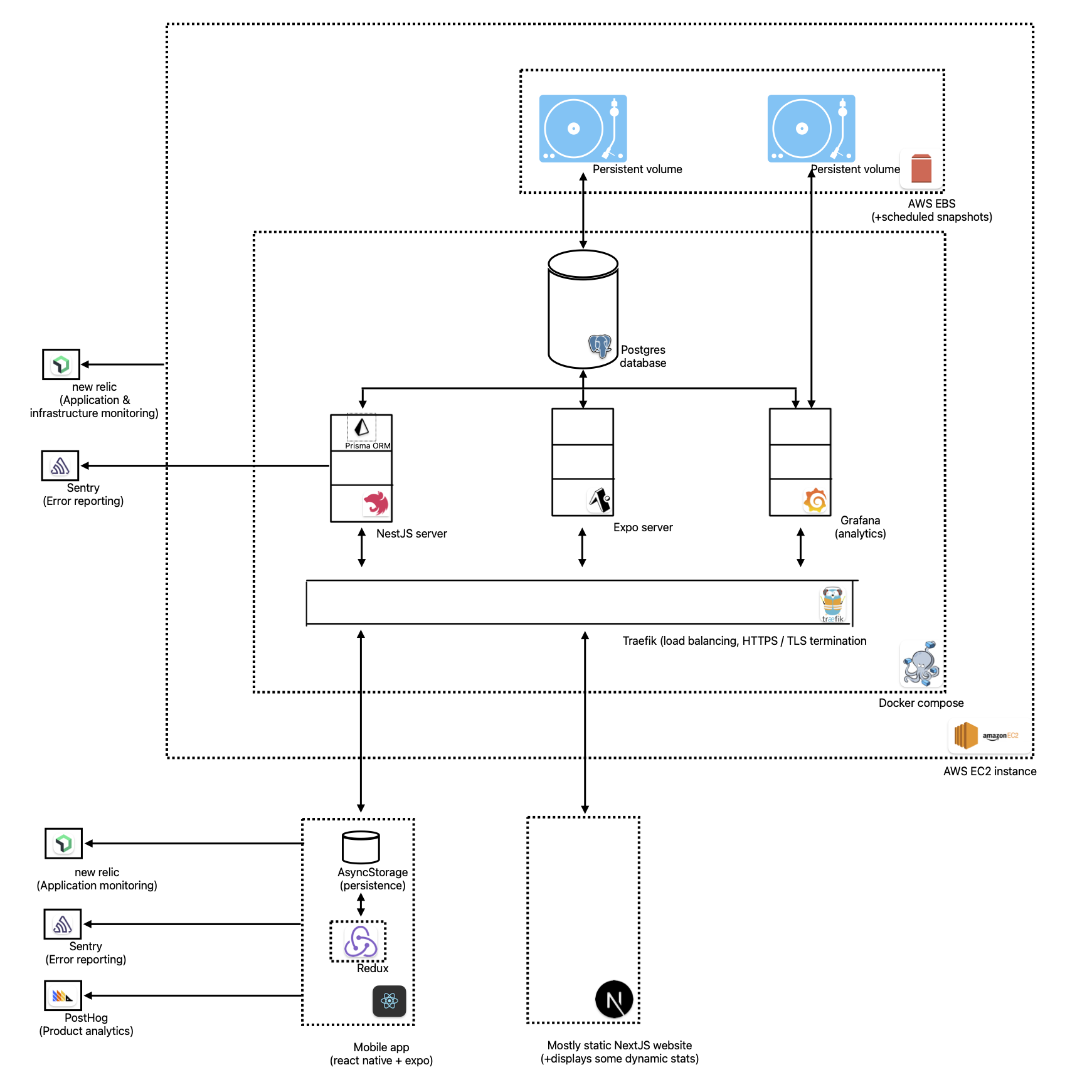
Infrastructure
Where the code runs
Now I had to decide where my server and database code would run. There are lots of options here, but they broadly fall into either:
- Platform as a Service or PaaS
- eg: Heroku, Vercel, Netlify, Elastic Beanstalk
- Infrastructure as a Service or IaaS
- There’s also a category that’s sort of a hybrid between the two
- eg: Coolify
I decided to go with Amazon EC2. I considered also setting up Amazon RDS for my database, but decided against it because of cost (and I figured it’d be a learning experience to fully manage my own database).
For disaster recovery in case something goes wrong with my instance, I also set up daily volume snapshots, which more or less put an upper bound on how much data I could potentially lose.
Containerization
To keep the environment reproducible and straightforward, I containerized the API server and the database using docker.
Service orchestration wasn’t too hard since everything was running on one host, so it was done using docker compose.
TLS / HTTPS
API requests needed to be encrypted using https to prevent man-in-the-middle attacks. This could be done on the API server level, but it’s usually more scalable to do it at a higher level through a reverse proxy. I used traefik to function as my reverse proxy.
I set up certbot and Let’s Encrypt to generate HTTPS certificates on schedule before they expire. All of this was set up to work on my docker compose setup.
Monitoring
I needed a way to know when something went wrong, something other than emails from angry users. For this I set up 2 systems:
- Sentry
- Sentry alerts me on errors thrown either on the server or on the app
- New Relic
- New Relic also picks up on errors, but does a lot more. It can be set up to alert on lots of different scenarios where an error might not be thrown.
- For example it can ping me if there’s been an increased rate of HTTP failure codes in a given time period, or if my request times are trending higher than normal.
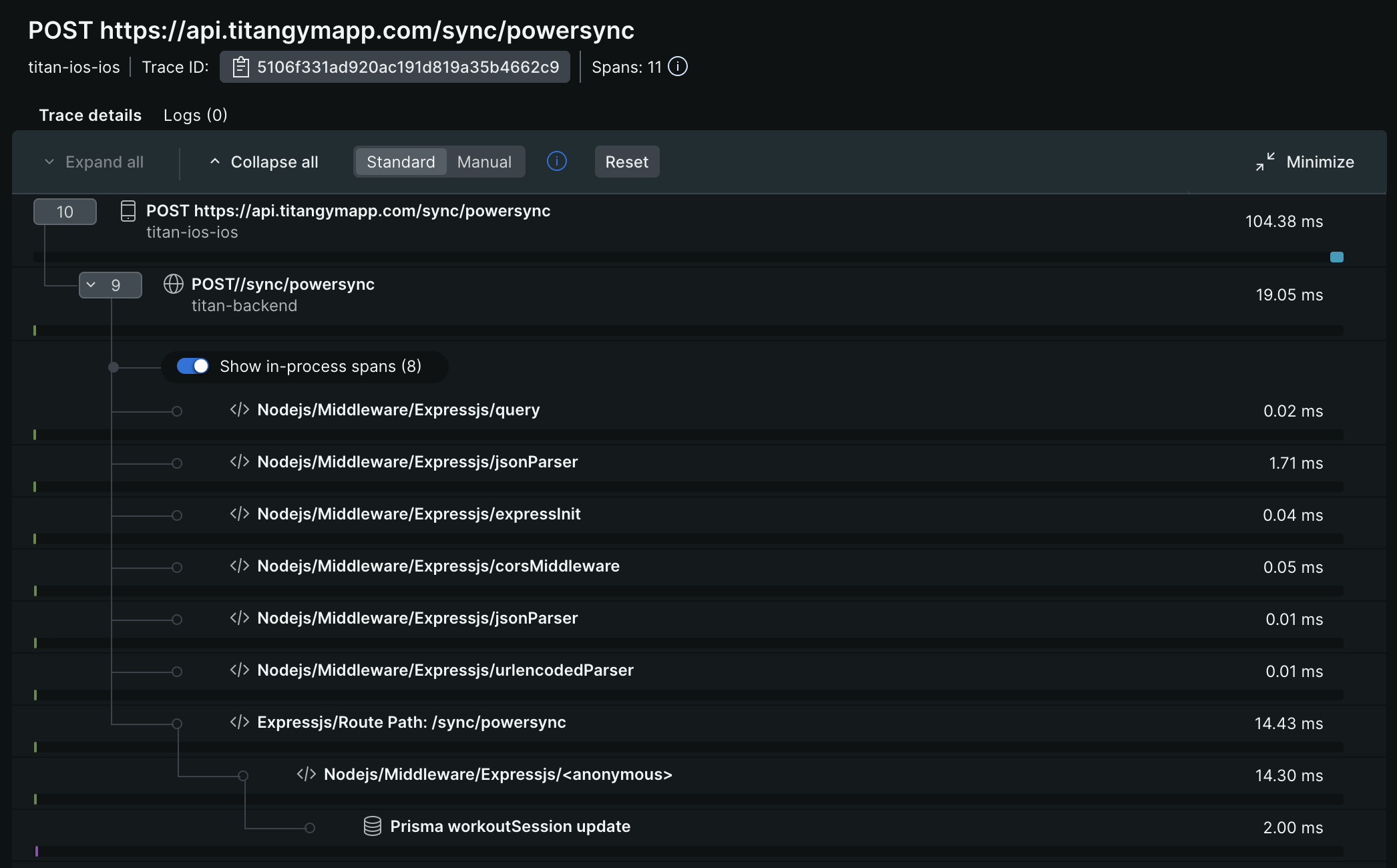
- I also have it set up on the app, which gives me distributed tracing, where I can track a user interaction to one or more API calls, to specific lines of code that runs on the server. This is a also a great way to debug application performance.
Personally I’m also a big fan of Datadog, but their free plan is very limited in comparison.
Product analytics
I needed one or more tools to let me see how real users were interacting with my app. I also wanted to be able to run quick A/B tests and see how things change. I decided to go with PostHog here. I love its design and simplicity. It has a generous free plan and supports a rich feature-set including experimentation, feature flags and nice visualizations for funnels.
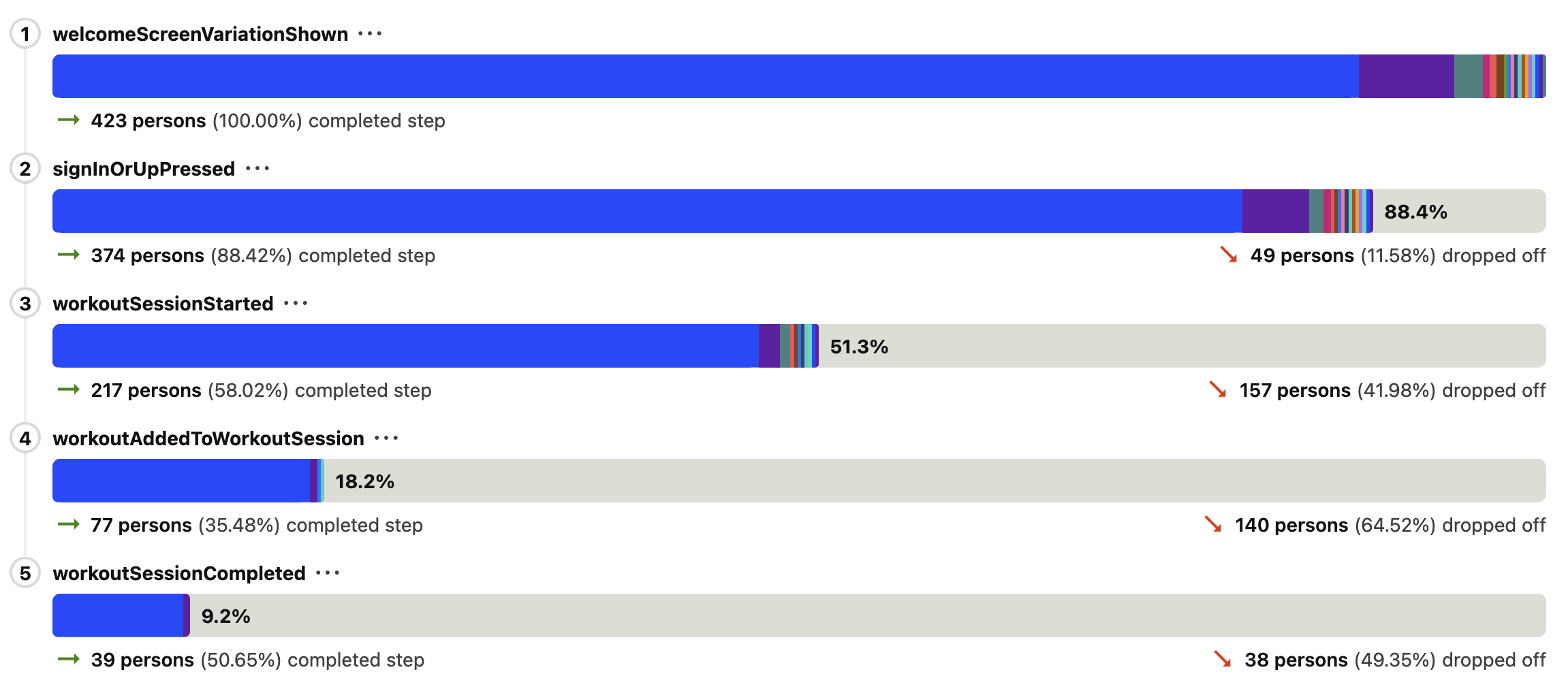
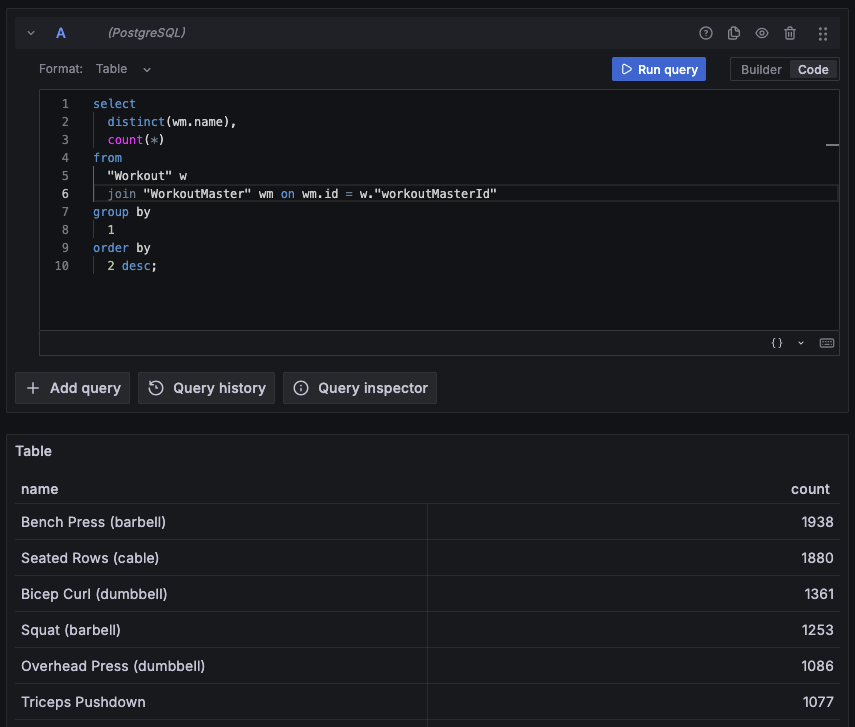
Posthog was great for analyzing events emitted from the app, but I also wanted to be able to run queries against the underlying data in the system.
For example, I can get a view of the most popular exercises on the system only if I’d explicitly sent PostHog events with this data from the start. To solve for this I’d need to be able to read the actual database, and for this I decided to go with Grafana. Grafana is a tool primarily aimed at use cases around monitoring and observability though, so this might not be the best choice here. Redash, Metabase and Apache Superset also look like good options I’ll likely consider in the future.
Thanks for reading
It’s been a lot of fun to build this app. I appreciate you taking the time to read this post. If you’re looking for a workout tracking app that values simplicity & functionality, I invite you to give Titan a try.